How BabySea uses Cloudflare to secure and control execution at scale
Date: April 19, 2026
By: Randy Aries Saputra
BabySea is execution infrastructure for generative media. That means we don't just run requests. We control how they execute across inference providers, with routing, failover, and lifecycle management.
As workloads scale, the problem is not just routing requests across providers. It's ensuring invalid, abusive, or malformed requests never reach execution, where every mistake has a real cost.
We use Cloudflare as the edge control layer to enforce correctness, security, and observability before requests reach our system.
This post breaks down how that works in production.
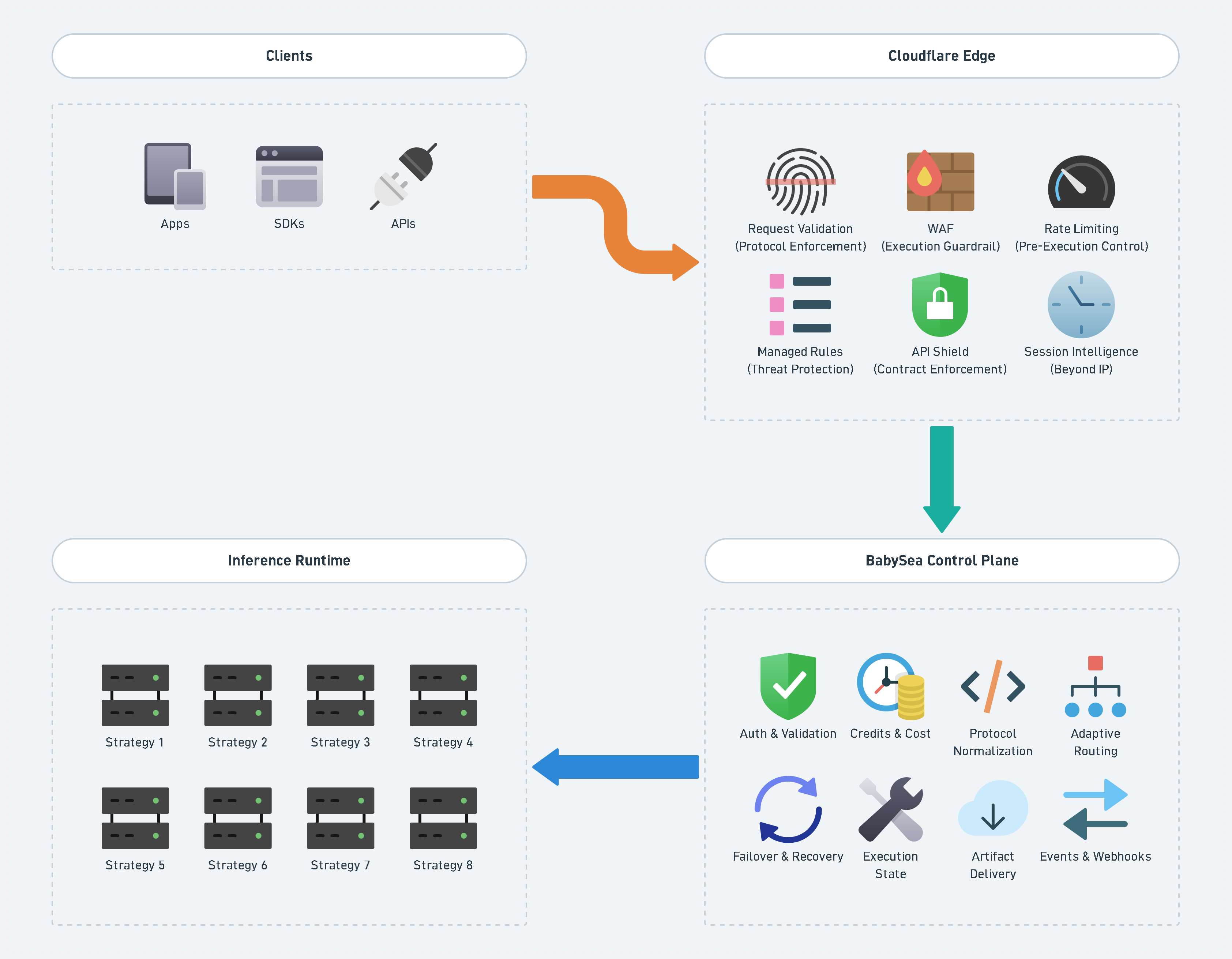
Architecture: edge as the first execution boundary
BabySea runs across three regions:
api.us.babysea.aiapi.eu.babysea.aiapi.jp.babysea.ai
Each region exposes the same API surface, backed by different infrastructure.
Cloudflare sits in front of all entry points and acts as a:
pre-execution control plane
Before a request reaches our application, it must pass:
- request validation ➜ protocol enforcement
- WAF ➜ execution guardrail
- rate limiting ➜ pre-execution control
- managed rules ➜ threat protection
- API Shield ➜ contract enforcement
- session intelligence ➜ beyond IP
These controls operate as independent layers, each enforcing a different constraint before execution begins.
What we are preventing is not theoretical:
- malformed requests reaching execution and wasting compute
- repeated invalid calls exhausting system capacity
- leaked API keys being used across distributed clients
- schema drift between providers causing runtime failures
Each layer exists to eliminate a specific failure mode before it reaches the control plane.
1. Request validation as protocol enforcement
Before applying any higher-level rules, we enforce basic protocol correctness:
- block non-HTTPS API calls
- block unsupported HTTP methods
- enforce JSON-only POST bodies
This ensures:
only structurally valid requests are processed further
Without this layer, invalid requests would propagate deeper into the system and fail after resources have already been allocated.
2. WAF as execution guardrail
We don't treat WAF as a security add-on. We treat it as:
execution constraint enforcement
We explicitly reject malformed or suspicious patterns:
- path traversal attempts
- injection patterns
- malformed headers
This ensures:
only valid execution paths reach the system
Without this layer, malformed requests would propagate into execution, where failures become expensive instead of cheap.
Abuse and scanning protection
We aggressively block automated scanning:
- sqlmap, nuclei, nmap, ffuf, burpsuite
- high-threat browser traffic is challenged
This removes:
background noise before it becomes load
Edge hardening
We added rules for:
- oversized Authorization headers
- duplicate Transfer-Encoding headers (request smuggling)
Even if upstream systems can handle these, we block them at the edge:
fail fast, before origin cost is incurred
3. Rate limiting as pre-execution control
Rate limiting is not just protection. It shapes system behavior.
We apply multiple layers:
Global API limit
xrequests per minute per IP (pre-auth)
Auth protection
xfailed auth attempts ➜ temporary block
Endpoint-specific limits
- playground ➜ burst control
- webhook ingestion ➜ flood protection
- cron endpoints ➜ strict limits
These rules ensure:
untrusted clients cannot dominate execution capacity
Without rate control at the edge, invalid or abusive traffic would compete directly with legitimate execution workloads.
4. Managed rules as threat protection
We leverage Cloudflare managed protections:
- OWASP rule sets
- Cloudflare threat intelligence
- automated bot detection
This layer handles:
known attack patterns and global threat signals
It allows us to absorb common threats without pushing that complexity into the application layer.
5. API Shield: enforcing contract at the edge
The most important layer is API Shield.
We define our API surface using OpenAPI:
- 15 endpoints per region
- deployed across 3 regions
- 45 operations total
Cloudflare validates incoming requests against this schema.
What this gives us
- invalid parameters ➜ detected immediately
- unknown endpoints ➜ logged as anomalies
- malformed requests ➜ visible before the application layer
Without schema validation at the edge, invalid requests would only fail inside the application layer, after resources have already been consumed.
6. Session-based intelligence (beyond IP)
Traditional rate limiting is IP-based. That breaks in real systems:
- shared corporate NAT
- distributed attackers
- leaked API keys
We track sessions using:
Authorizationheader as identity
This enables:
- per-key behavioral profiling
- anomaly detection
- request sequence tracking
Result:
- volumetric abuse detection
- enumeration detection
- per-customer visibility
All enforced at the edge.
IP-based control alone cannot reliably identify abuse in distributed systems.
Session-level tracking allows us to enforce behavior constraints per identity, not per network.
Layered execution control model
Client Request
↓
Cloudflare Edge
├─ Request Validation (Protocol Enforcement)
├─ WAF (Execution Guardrail)
├─ Rate Limiting (Pre-Execution Control)
├─ Managed Rules (Threat Protection)
├─ API Shield (Contract Enforcement)
├─ Session Intelligence (Beyond IP)
↓
BabySea Control Plane
├─ Access Control
├─ Credit Lifecycle
├─ Protocol Translation
├─ Policy Routing
├─ Failover Orchestration
├─ Failure Handling
├─ Artifact Pipeline
├─ Event System
↓
Execution LayerThe control plane defines how execution should happen. The execution layer carries it out.
Each layer removes a different class of risk before it propagates.
no single failure allows invalid or abusive execution to reach the system
Execution is stateful, not just request-based
Once a request passes edge validation, it enters a lifecycle that must remain consistent across providers, retries, and failures.
We treat execution as a controlled state machine:
- request accepted ➜ generation created
- credits reserved before execution
- provider execution begins
- result confirmed inline or via webhook
- credits finalized as charge or refund
This prevents critical failure classes:
- double execution across providers during failover
- double charge when multiple providers complete
- orphaned jobs when upstream systems fail
- inconsistent state between storage, database, and providers
Execution is not just calling a provider.
it is maintaining correctness across asynchronous, multi-provider systems
A key part of that lifecycle is ordering. We create the generation record before reserving credits, so billing and state transitions are attached to a single durable generation ID from the start.
const { data: record } = await adminClient
.from('file_assets')
.insert({
account_id: accountId,
generation_data: {
generation_provider_order: toProviderArray(providerOrder),
generation_status: 'pending',
},
})
.select('id, account_id, generation_id')
.single();
const { reserved } = await reserveCredits(
accountId,
model,
record.generation_id,
undefined,
generationResolution,
);That ordering matters. It avoids reserve-then-cleanup ambiguity and makes every economic event traceable to the same lifecycle record.
Billing correctness is enforced as an invariant
In a multi-provider execution system, billing correctness cannot depend on good luck or a single success path.
We enforce a simple invariant:
one generation can reserve once, charge once, and refund once
That rule is backed by the database, not just application logic.
CREATE UNIQUE INDEX IF NOT EXISTS idx_credit_ledger_charge_idempotent
ON public.credit_ledger (generation_id) WHERE type = 'charge';
CREATE UNIQUE INDEX IF NOT EXISTS idx_credit_ledger_refund_idempotent
ON public.credit_ledger (generation_id) WHERE type = 'refund';Credits are also reserved atomically. That prevents concurrent requests from both passing a balance check and spending the same balance twice.
UPDATE public.credits
SET tokens = tokens - p_tokens
WHERE account_id = p_account_id
AND tokens >= p_tokens;This is what turns billing into a system property instead of a best effort.
Failover is controlled, not optimistic
Failover is usually presented as a simple fallback story. In practice, it is a consistency problem.
A provider can fail late. A webhook can arrive after the next provider has already been considered. Storage may already contain a completed output even when the local request path thinks it failed.
We account for that explicitly.
First, provider order is reordered by health so degraded providers are moved back without changing the public execution contract.
const { reordered: sequence } = await reorderByHealth(baseSequence);
providerOrder = sequence.map((s) => s.provider).join(', ');Then, after a failed attempt, we check storage and database state before spending money on the next provider.
const { data: storageFiles } = await adminClient.storage
.from('file')
.list(`${record.account_id}/${record.generation_id}`);
if (storageFiles && storageFiles.length > 0) {
result = {
provider: step.provider,
predictionId: 'webhook-delivered',
status: 'succeeded',
providerModelId: step.providerModelId,
};
break;
}This is the difference between "trying another provider" and controlling a distributed execution lifecycle.
Provider abstraction is a contract, not a passthrough
A multi-provider system degrades quickly if provider-specific fields leak into the public API.
We keep the public contract unified and intentionally normalize provider differences into BabySea's own schema model.
That includes rules like:
ratio-based sizing instead of exposing raw width and height intersection of supported formats across active providers pricing dimensions modeled as core execution fields, not provider-specific knobs
A simplified example:
// width: z.number().int().min(256).max(1440).optional(),
// excluded - uses ratio-based sizing, not pixel dimensionsAnd at the schema level, core execution fields are ordered and enforced consistently across models:
generation_prompt
generation_ratio
generation_output_format
generation_output_number
generation_input_file
generation_duration
generation_resolution
generation_generate_audio
generation_provider_orderThis is what lets multiple providers behave like one execution system instead of many inconsistent APIs.
Edge and tenant boundaries matter as much as model execution
Execution correctness is not only about providers. It is also about where requests are allowed to exist.
Our middleware enforces API-only domains, separates marketing and dashboard surfaces, and strips headers that should never influence account identity.
if (!pathname.startsWith('/v1')) {
return new NextResponse(
JSON.stringify({
status: 'error',
error: {
code: 'BSE1001',
type: 'not_found',
message: 'Restricted access',
},
}),
{ status: 404, headers: { 'Content-Type': 'application/json' } },
);
}
const requestHeaders = new Headers(request.headers);
requestHeaders.delete('x-account-id');
return NextResponse.next({
request: { headers: requestHeaders },
});That matters because execution systems are also multi-tenant systems. The edge has to enforce those trust boundaries before requests reach the control plane.
Execution must be protected before it begins
In generative systems, execution is the most expensive part of the pipeline.
Every invalid request that reaches execution is not just an error. It is wasted compute, wasted time, and unnecessary cost.
Our design ensures that:
- invalid requests are rejected early
- abusive behavior is constrained before execution
- only valid, well-formed requests reach the control plane
This is why edge enforcement is not optional. It is part of execution itself.
Why this matters for generative media
Generative workloads are fundamentally different:
- long-running execution
- high cost per request
- unpredictable input
- multi-provider dependency
Without strict edge control:
- invalid requests waste compute
- abuse becomes expensive quickly
- provider failures cascade
Cloudflare allows us to enforce: correctness before execution.
Closing
At BabySea, execution infrastructure is not just routing and failover.
It is:
- controlling what enters the system
- validating it before execution
- observing behavior at scale
- enforcing constraints at the edge
Cloudflare is not just a security layer for us.
It is where execution constraints begin.
By the time a request reaches our system, it has already been validated, constrained, and shaped.
Execution is not just what happens inside the system.
it starts at the edge